By Andrew Hamlet | andrewshamlet@gmail.com
This case was presented at The New York Chapter of the American Association for Public Opinion Research in early 2016 and published in Data Visualization Made Simple: Insights into Becoming Visual, Sosulski, K, Routledge: New York.
In November 2015, a group of NYU Stern MBA students (Troy Manos, Keita Shimizu, Tarang Dawer, and Andrew Hamlet) set out to study whether Twitter can predict the outcome of the U.S. presidential election. Based on preliminary research of the opinions of major news outlets, the answer was not clear. There are many different viewpoints on the value of social media, specifically Twitter, to predict election outcomes. Some see any publicity as good publicity.
“What people say on Twitter or Facebook is a very good indicator of how they will vote.”
“In 2010, …Twitter data predicted the winner in 404 out of 435 competitive [congressional] races.”
“If people must talk about you, even in negative ways, it is a signal that acandidate is on the verge of victory”
– The Washington Post
While others questioned if social media could provide a direct measurement of voter intention. To what extent could interactions on Twitter signal a specific outcome? News sources commented:
“…Twitter is a notably non-representative sample of people.”
“At last count, eight percent of American adults use Twitter daily; only 15 percent are on it at all.”
“In the best of circumstances it is possible to detect the online projections and manifestations of existing offline phenomena that tend to coincide with particular outcomes or events.”
– The Atlantic
What do you think? How would you begin to explore these questions?
To even begin to answer if Twitter can predict the outcome of a presidential election you would have to look at the data. What data would you need? You could begin with a social graph of each presidential candidate and their interactions and following on Twitter as seen in Table 1.
| Date | Favorites | Followers | Mentions | Party | Politician | Retweets |
| 2/25/16 | 2353 | 6435 | 5899 | Democrat | Bernie Sanders | 1106 |
| 2/26/16 | 4455 | 7209 | 5016 | Democrat | Bernie Sanders | 2243 |
| 2/27/16 | 3469 | 5147 | 7551 | Democrat | Bernie Sanders | 1520 |
| 2/28/16 | 0 | 6144 | 2901 | Democrat | Bernie Sanders | 0 |
| 6/16/15 | 1711 | 7262 | 7681 | Democrat | Hillary Clinton | 813 |
| 6/17/15 | 586 | 6789 | 6329 | Democrat | Hillary Clinton | 312 |
| 6/18/15 | 2618 | 6646 | 5380 | Democrat | Hillary Clinton | 1688 |
| 6/19/15 | 1337 | 6882 | 4734 | Democrat | Hillary Clinton | 674 |
| 6/20/15 | 1259 | 5787 | 5333 | Democrat | Hillary Clinton | 959 |
| 6/21/15 | 1915 | 6464 | 3950 | Democrat | Hillary Clinton | 655 |
Table 1. A sample of Twitter data collected on the presidential candidates and the volume of tweets, the audience engagement, and Twitter followers
This is exactly what the team did. However, the data alone did not present any interesting findings. They needed to make sense of the data and developed a methodology for analyzing the Twitter data. They created three key metrics: 1) volume 2) engagement and 3) followers, see Figure 1.
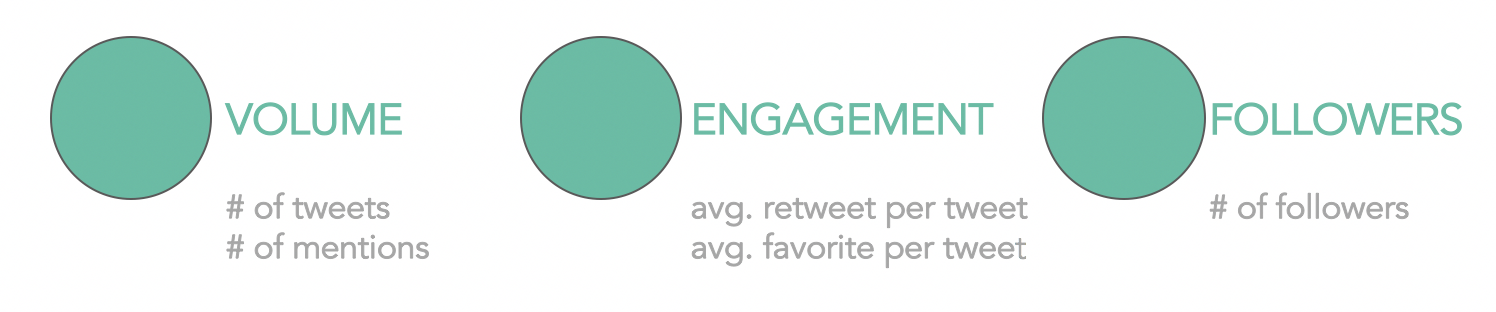
Figure 1. Methodology for analyzing Twitter data, outlining the three-key metrics.
Volume was measured using two inputs: the number of tweets defined as the daily count of tweets from the respective profile and by the number of mentions defined as the daily count of tweets referencing the respective profile.
Engagement was measured by two inputs: the average retweet per tweet defined as the daily average retweets per tweet from the respective candidate profile and the average favorite per tweet, which was the daily average favorites per tweet from the respective candidate profile.
Followers were measured by the number of followers defined as the daily amount of followers gained by the respective candidate profile
These metrics were gathered daily from 11/1/2015 to 11/30/2015. Each metric was averaged by month, normalized across the candidates, equally weighted, summed for a Total Composite Score, and sorted in descending order to produce a ranking.
- Averaged by month
[22, 20, 25, 15, 15, 37, 25, 38, 10, 23, 16, 20, 13, 22, 25, 12, 13, 7, 31, 28, 45, 19, 18, 17, 20, 9, 8, 18, 17, 13] / [30]
[20]
- Normalized across candidates, divided by the maximum for each metric
[20, 10, 10, 12] / [20]
[1.00, 0.50, 0.50, 0.60]
- Equally weighted
number of tweets + number of mentions + avg. retweet per tweet + avg. favorite per tweet + number of followers
- Summed for Total Composite Score
1.00 + 0.93 + 1.00 + 1.00 + 1.00 = 4.93
- Sorted in descending order to produce a ranking
The team appended the original data table with their new metrics TW Followers, TW Mentions, TW Retweets, TW Tweets, and Composite Score.
Based on the methodology, the team conducted an analysis of leading candidates from both political parties for the 2016 Presidential Election. They showed what the presidential race looked like on Twitter based on their analysis (see Figure 2). The heat map suggests Donald Trump, when compared to the other candidates, maximized his Twitter presence. Additionally, the heat map shows that the race (as viewed on Twitter) was closer between Democrats than it was among Republicans.
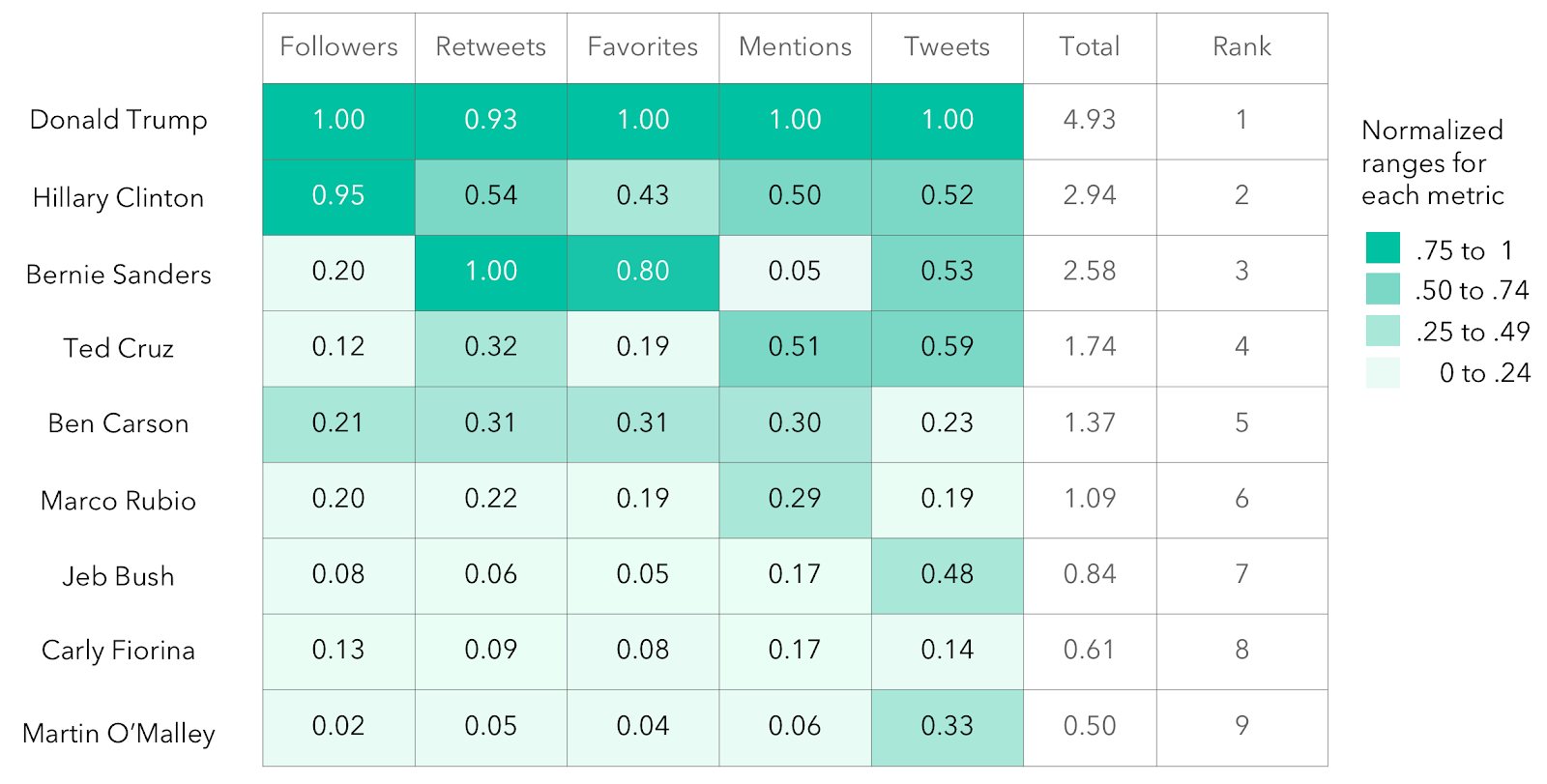
Figure 2. A heat map displaying Twitter activity across the presidential candidates with Donald Trump leading during the timeframe 11/1/2015 – 11/30/2015.
The heat map then presents the rank of each candidate according to the calculated metrics. The darker shading was used to indicate relative leadership in a category as compared to others. The metrics are divided into four subgroups that correspond the ranges 1 to .75, .74 to 50, .49 to .25, and .24 to 0. Each subgroup was assigned a shade of green.
After analyzing the data from November 2015, Andrew observed how the model would adjust over time. To do this, he categorized the candidates by political party and applied the methodology through the presidential primaries. Andrew showed how the two leading candidates from the Republican and the Democrat parties ranked according to the model from June 2015 through February 2016, see Figure 3.
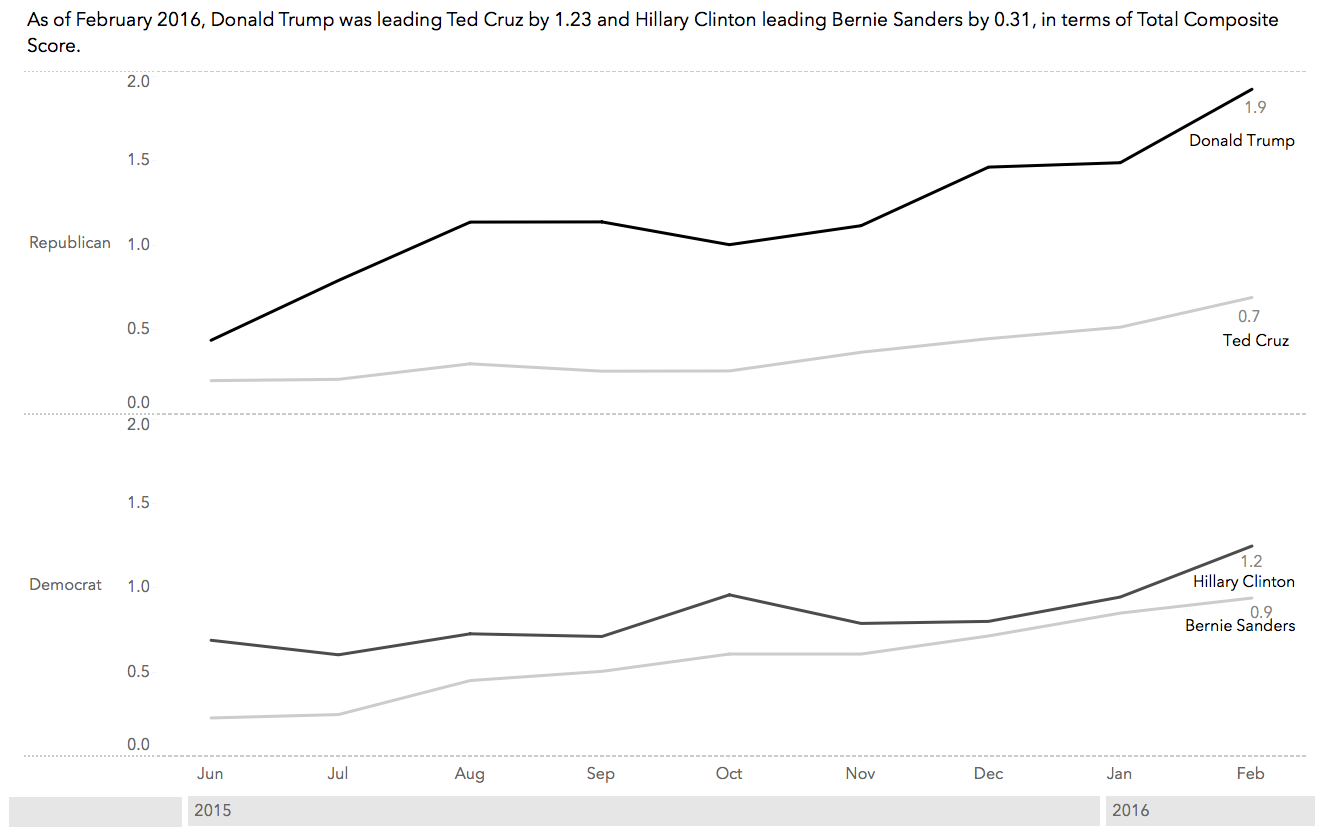
Figure 3. Time series of social media behaviors on Twitter showing Donald Trump leading Ted Cruz and Hillary Clinton more narrowly leading Bernie Sanders through February 2016.
As of February 2016, Donald Trump was leading Ted Cruz by 1.23 and Hillary Clinton leading Bernie Sanders by 0.31, both in terms of Total Composite Score. Thus, the line chart presents a smaller gap between Hillary Clinton and Bernie Sanders than between Donald Trump and Ted Cruz.
Around March 2016, as it became clear the race would be between Donald Trump and Hillary Clinton, the methodology was applied to the two nominees. The following time series display (see Figure 4) illustrates how Donald Trump and Hillary Clinton ranked according to the model by month from June 2015 through October 2016.
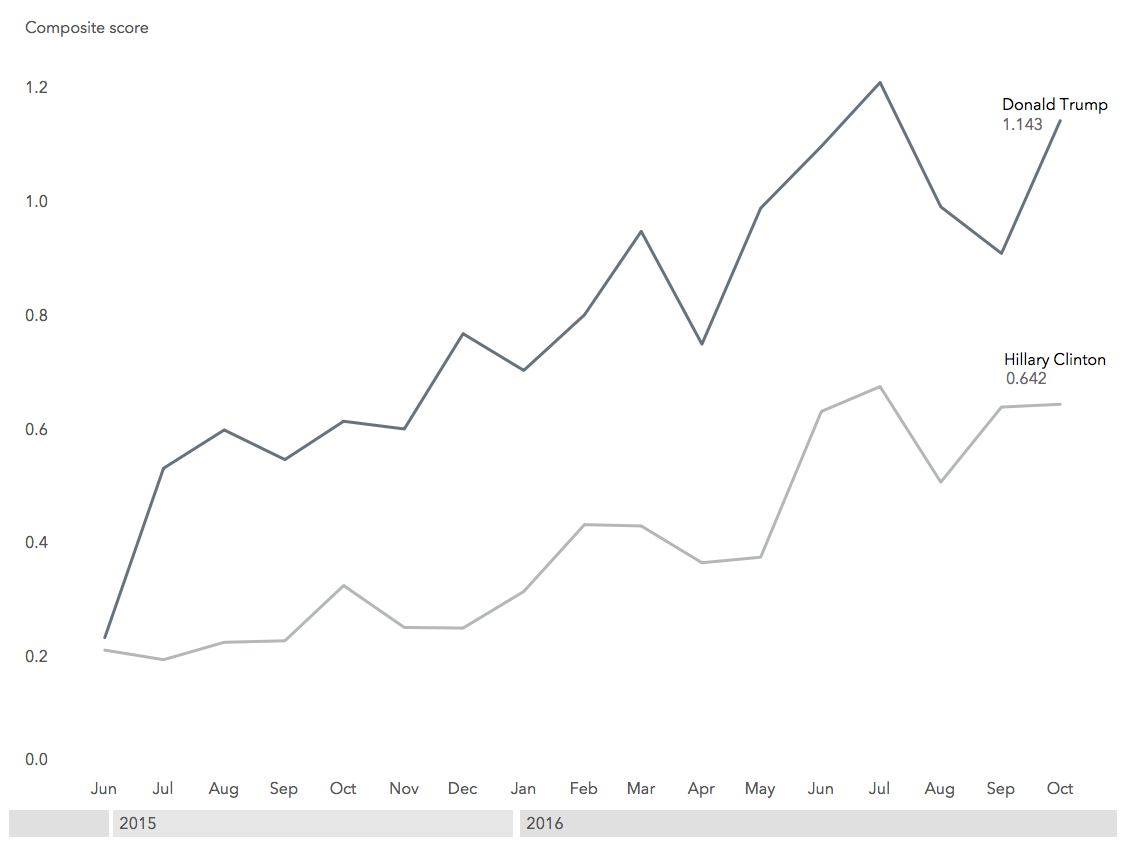
Figure 4. Time series of social media behaviors on Twitter showing Donald Trump leading Hillary Clinton throughout the primary and general campaigns.
Donald Trump would go on to win the 2016 Presidential Election. Many cite social media as a contributing factor in the outcome. Or perhaps the insights presented are more indicative of Clinton’s defeat than Trump’s win?
August 6, 2017
“Everyone understands that what gets shared online matters now.”
– The New York Times
July 8, 2107
“Given the role that Twitter played in the presidential campaign, we analyzed Mr. Trump’s and Mrs. Clinton’s Twitter accounts in the six months before the election. We found that Mr. Trump benefited by using moral-emotional language (a 15 percent increase in retweets) but Mrs. Clinton did not.”
– The New York Times
Visualization simplifies the complex, which is the beauty of the medium. When performed well, it presents information clearly; however, interpreting the information is not always so clear. This was the case for the Twitter prediction project. During the election, the prevailing belief was Trump would not win. The model displayed a different story. Between the perspectives existed the insight. Though, arriving at the insight often involves more questions, such as
- Who engaged on Twitter with Donald Trump?
- Is there something about the content of the tweets that leads the audience to engage?
- If Twitter represents mass public opinion, why did the engagement rates not translate to the popular vote?
- What is the relationship between social and traditional media?